
Vibe Code Your
A/B Tests
Run your first real A/B test this week – vibe-coded in one Claude Code session through PostHog, measured to the conversion that matters, and decided the honest way when significance is out of reach.
The Tool We
Kept Losing
A couple of years ago, pretty much everyone ran A/B tests on Google Optimize. Three parallel tests, free, wired neatly into the old Google Analytics. Then Google decommissioned Universal Analytics, moved everyone to a GA4 that nobody liked – and in the same swing, killed Optimize. That was the moment a lot of us walked away from the whole Google stack.
I moved to VWO, which was genuinely good, with reasonable pricing for small traffic (a free tier somewhere around ten thousand visitors a month). Then AB Tasty bought them – and even before that, the price ladder kept climbing. It's almost a meme by now: every B2B SaaS is secretly an enterprise company that just doesn't know it yet. Fair enough as a business decision. It just left smaller teams out in the cold.
Three free parallel tests – decommissioned alongside Universal Analytics.
Great for small teams, until the ladder climbed toward enterprise.
One affordable stack – and the setup is now a single conversation.
Then I found PostHog, and it quietly became the one tool that replaced a shelf of others: the analytics that succeeded Universal Analytics, the product analytics I used to pay Amplitude for, the session recordings I used Hotjar for, even the expensive pipelines I ran through Supermetrics – and, it turned out, the A/B testing I'd lost twice over.
Here is the part that actually changed the game. The thing that used to need a paid tool, a developer and weeks of setup is now a single Claude Code session. And the point was never the test itself. It's what cheap, fast experimentation unlocks: you learn faster than your competition what wastes your time and money and what actually converts. If you've followed this series, you know the ground we've covered – strategy in the codebase, content as a skill, the funnel and its lead magnet, the analytics instrument, and then the traffic. The instrument did its job and told us the truth: traffic wasn't the bottleneck anymore. The page was. This is the week we fix that – the last move of the six.
One Sentence,
One Experiment
When the numbers from the ads came in and the conversion rate disappointed, I had a hunch: people weren't immediately feeling the value of what they'd get on the other side. The old landing page for the “First Week After Yes” lead magnet showed a static sample plan. So I opened Claude Code and said, more or less, one sentence: create an experiment in PostHog, a fifty-fifty split, control is the old static plan, and the treatment shows a visualization of the conversation with the agent that helps a bride plan her first week – with an example budget.
What Claude did with that one instruction: it set up the experiment in PostHog, then made the actual code change so there aren't two URLs to split traffic between – it's one page, and PostHog handles the fifty-fifty split, so the comparison stays fair. It wired the conversion events that matter: a signup-start (the moment someone clicks the call to action and lands on the signup screen) and a completed signup (they finish and arrive in the app).
The genuinely impressive part was everything I didn't have to think about. It made the tracking conform to our consent policy and stay correct as people move across subdomains – the kind of thing that quietly breaks an experiment. It tested the whole thing in a browser to see which events actually fired. A day into the traffic we even caught a couple of tracking gaps together and fixed them on the fly – none of which I could have done myself. Start to finish I was happy with it in about fifteen minutes. In VWO or Optimize this was a day of work – and honestly, the conversation-style variant couldn't have been built in those visual editors at all.
Help me set up an A/B test on my highest-traffic landing page using PostHog, step by step. First ask what I'm testing and why – my hypothesis, the page URL, and the single conversion event that actually matters to me (a signup or purchase, not a click). Then create the experiment and feature flag in PostHog with a 50/50 split, and make the code change so it stays one URL with the variant resolved server-side (no flicker), bucketed on a consent-safe first-party cookie that survives moving between my www and app subdomains. Track a primary conversion event plus one or two secondary events, and filter out my internal and test traffic. Test it in the browser to confirm the events fire, show me the full setup for review, and let me launch it myself.Don't Guess,
Watch the Replays
You don't pick what to test from an opinion in a meeting. You pick it by watching real people. PostHog records the same sessions you already pay it to capture, and I watched a handful of them on the lead-magnet page. The pattern was quiet but consistent: people scrolled to the sample plan, looked at it – and left.
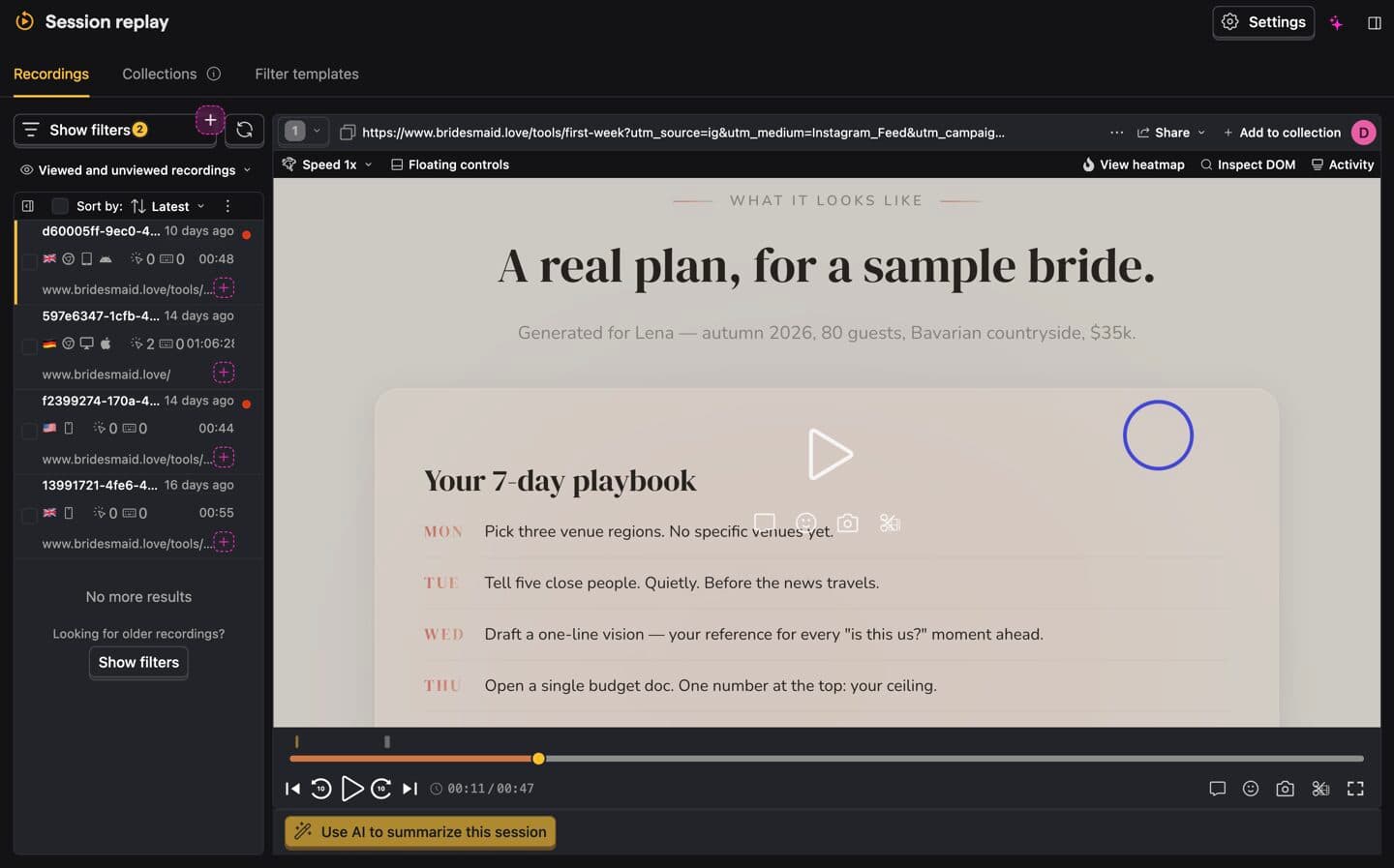
Visitors reached the static sample plan, paused on it, and exited the session – over and over.
Maybe it reads as too generic – not enough to feel the value. Show the living conversation instead of a flat list.
I want to be honest about what that is: a judgment call, not proof. It was pure intuition that the sample plan was the reason they left. That's exactly the right job for the replays though – they're the input, the thing that tells you where to look. The experiment is the output, the thing that tells you whether you were right. And as you'll see in a moment, this particular hunch only turned out to be half the story.
Throw Spaghetti,
Then Get Scientific
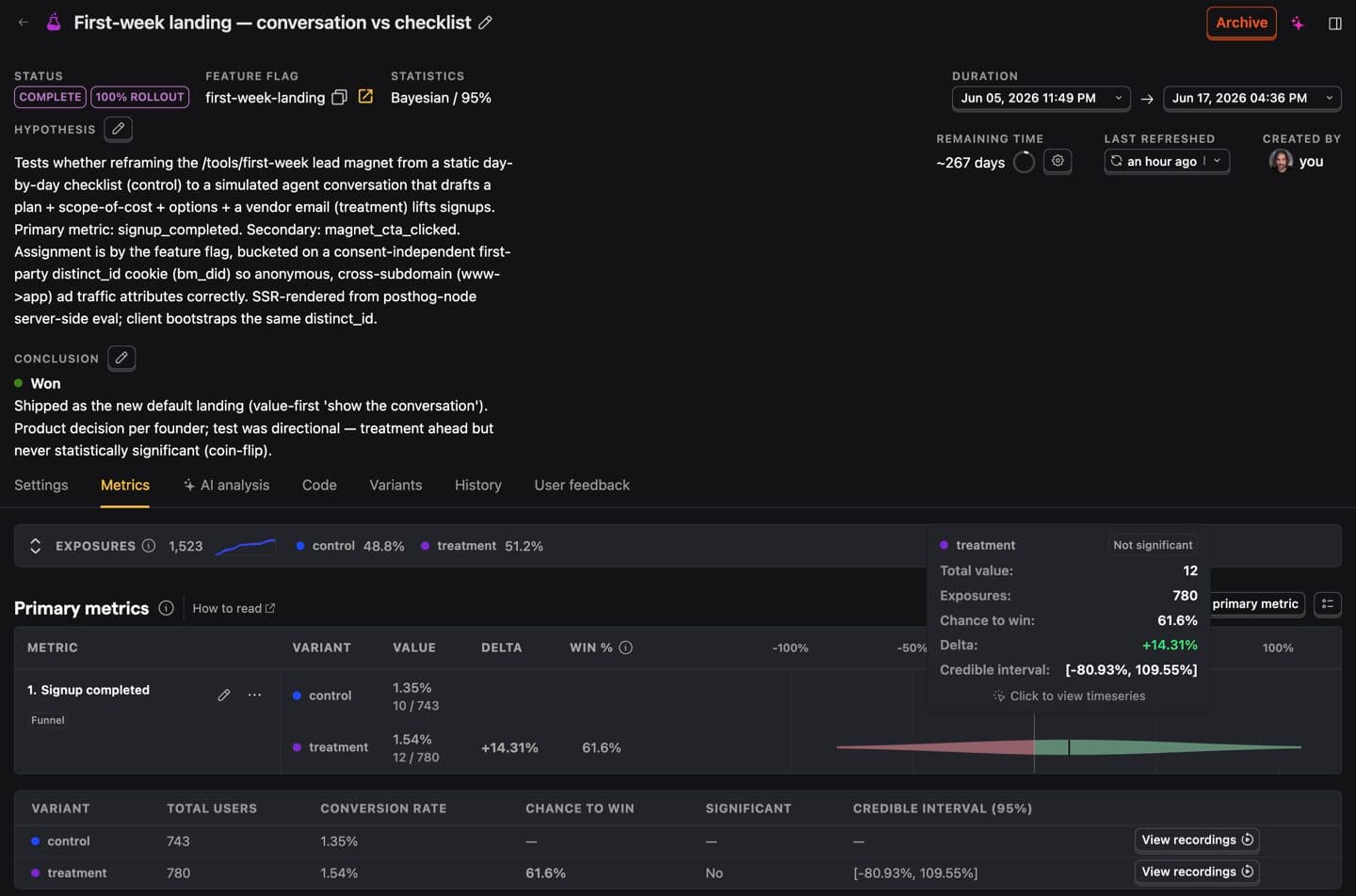
Here's the result, read honestly. The conversation variant came out ahead on every metric we tracked – more clicks, more completed signups. A clear directional lift. And not one bit of it was statistically significant.
Directional on every metric – none significant. Chance to win sat near 62%, a coin-flip, and we'd have needed roughly 26,000 visitors per arm to call it. PostHog under-counts versus the database, so read these as a fair side-by-side comparison, not as absolute totals.
So what do you do with a result that's ahead but never crosses the line? My rule is simple and, I'll admit, a bit heretical: if I see a consistent uplift of more than ten percent over several days, I'm confident enough to ship it. Both numbers here cleared that bar – +14% on completed signups, +11% on clicks. You often cannot wait until the ninety-fifth percentile of a p-value at startup traffic – for this test, the honest math was about twenty-six thousand visitors per variant, which at our volume is well over a year away.
This is the pirate way to run it. Early on, before you're saturated on the optimization curve, it is far more effective to throw spaghetti at the wall and see what sticks than to run minute, single-variable tests. Test bold, high-contrast changes. Then, once saturation hits and every fraction of a percent counts, you become more scientific. Rigor scales with you – it's not a gate you have to clear before you're allowed to move.
And you close the test so it doesn't dangle. I nominated the winner, shipped it to a hundred percent of users, and Claude removed the now-unnecessary code and flags. The learning went two places: into the experiment record in PostHog, and into our running A/B-testing journal – so the next test starts from what this one taught us.
My A/B test is ahead but hasn't reached statistical significance, and at my traffic it won't for a long time. Help me make an honest call and conclude it cleanly. First, read the results from PostHog and lay out each metric side by side – control vs variant, the relative lift, and how far it is from significance – without overstating anything. Then help me decide using a simple rule: a consistent multi-day uplift above ~10% is enough to ship at this stage; a coin-flip is not. If we ship, conclude the experiment in PostHog (roll the winner out to 100%), then remove the now-dead feature-flag code and the losing variant from the codebase so nothing dangles, and append a short entry to my A/B-testing journal: the hypothesis, the result, the decision, and what to test next.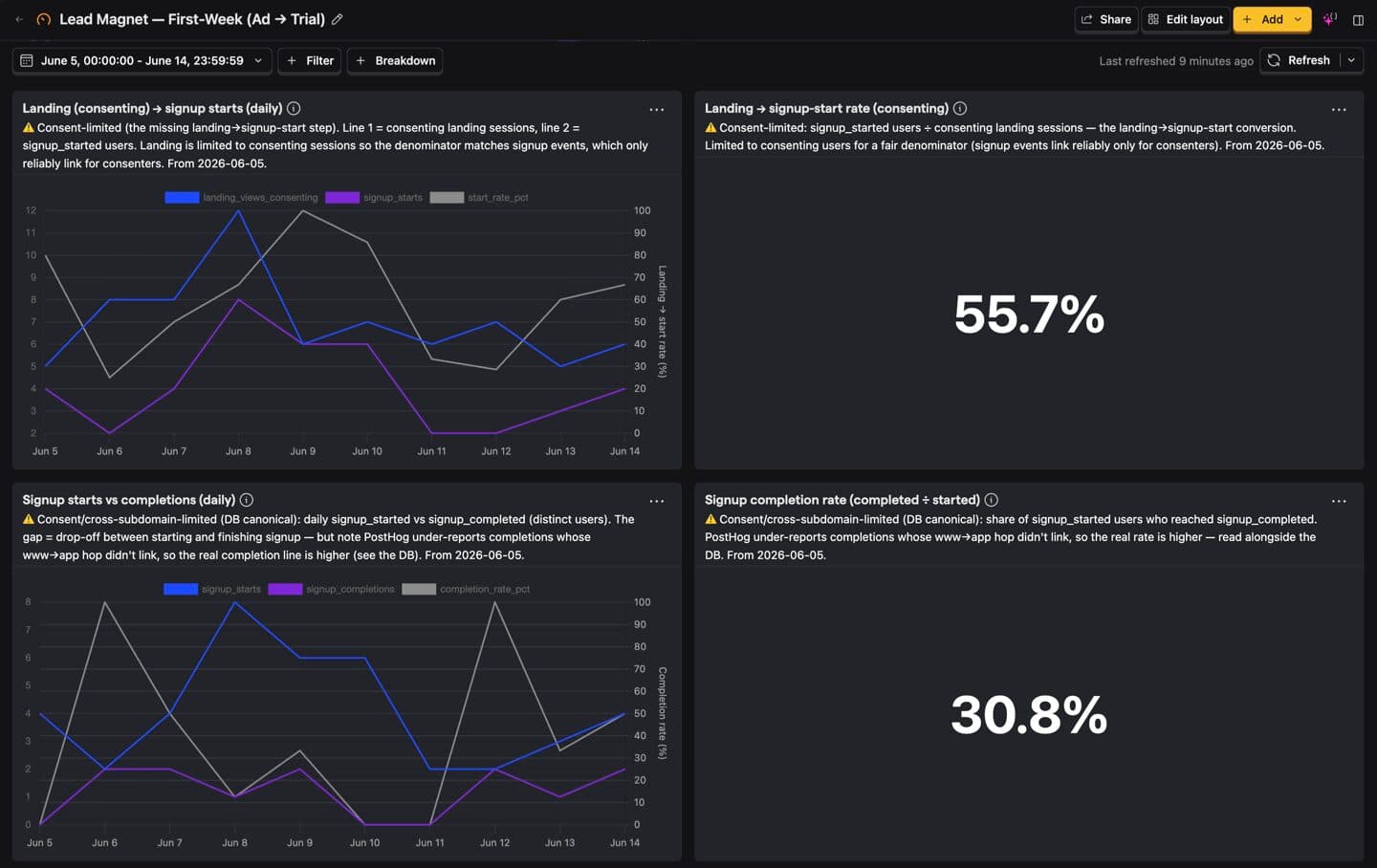
Now the deeper read – because the conversation only nudged things, which told me it wasn't the main problem. The dashboard I'd had Claude build for this page made the real leak obvious. People clicked the call to action just fine. But between starting the signup and finishing it, about two-thirds of them dropped. That felt like a bait-and-switch: you click expecting a free plan and instead hit an unannounced wall asking you to create an account. So the next test – running right now, no results to report yet – changes the CTA to name the next step before the click and adds a one-tap Google sign-in. Same loop, bolder swing.
Six Moves,
One Engine
Step back and look at the whole arc. Six weeks, six moves, all in one codebase: the strategy, the content, the funnel, the analytics, the traffic – and now conversion optimization, the move that turns all that traffic into customers.
Your move this week is the one I'd call the Spaghetti Test: run one real A/B test on your highest-traffic page. Vibe-code it behind a feature flag, point it at the conversion that actually matters, make the variant a bold swing rather than a timid tweak, and decide it on the totality of the signal – ship on a consistent multi-day lift, log what you learned, move to the next one. You're done when you have a running experiment, a real conversion event, a written decision rule, and a journal entry.
And here's where it's all heading. Every move in this series has been laying track toward a self-optimizing growth engine. It maps onto the levels of AI skill for founders I've written about: Level 6, where the codebase starts to heal itself and, on the growth side, funnels and campaigns optimize themselves and your knowledge base expands itself – data-driven systems that continuously develop your product and your marketing. This A/B-test loop is the first real brick of that future. Knowing which problem you actually have – the discipline the Growth Codex calls what to improve – is what makes a self-optimizing engine optimize the right thing. That engine is where this whole show goes next season.
If you want to watch the entire setup happen live – the experiment, the session recordings, the honest read of the results – that's exactly what I'm doing at the next Pirate Lab.
Cheers,
Ben
Ready to Go Deeper?
Pirate Lab
·Wed, Aug 12 · 18:00 CESTFree weekly online workshop where we walk through the week's Captain's Insight together. Bring your project, get live feedback.
Vibe Coding Cologne
·Wed, Aug 5 · 18:30 CESTMonthly in-person meetup in Cologne. Talks from Ben and local founders, drinks, building alongside the community.
Vibe Hackathon Cologne
·Fri, Sep 4 · 14:30 CESTIntensive on-site weekend hackathon – build and ship something real in 48 hours with other founders in Cologne.
Pirate Forge
·In 60 days · Wed, Sep 306-week cohort program combining build and grow tracks. Weekly workshops, accountability, the founders you'd want to ship next to.
Questions & Answers

Founder from Cologne with 15 years of startup experience across 9 ventures. After helping thousands master growth marketing, Ben learned vibe coding from scratch and launched CaptAIn within three months. He leads the Vibe Coding Cologne community, blending real founder experience with teaching clarity.