
Why Growth Strategy
Belongs in Your Codebase
Agents don't lack capability – they lack context. Once your builder and growth knowledge lives in one searchable place, a new level of performance unlocks.
No Context,
No Help
Earlier this year I noticed something quiet about how I work. I hadn't planned it. My company's context had drifted, file by file, into the Pirate Skills codebase. The growth strategy. The OKRs. The content and story doc. The bottlenecks I kept tripping over. Each one started somewhere else – usually Notion – and at some point ended up as a markdown file inside the repo, groomed across quarterly revisions, sitting one folder over from the product itself. I just observed it one day: I'm not really doing this in Notion anymore.
The catalyst was the latest Opus. Once I had a working agentic partner inside Claude Code, I wasn't willing to give that up. Most of my marketing work is connected to the website or the web app anyway. A prompt like let's build a new landing page for the next Vibe Hackathon now reaches a model that reads our Content & Story doc and gets the wording almost perfectly for our audience, drops in the right sign-up modal with attribution already wired, fires the right conversion events through PostHog, and pulls the upcoming hackathon date from the events database. So much of it just happens magically– because I knew what I wanted, and the agent could infer the rest from the context already living in the codebase. The whole thing felt alive, on the growth side and the builder side.
- Product code & UI
- Auth, payments, env configs
- The skills folder & CLAUDE.md
- README files & migration scripts
- Tests, schemas, anything checked in
- Strategy slides & decks
- Notion roadmaps & OKR pages
- The Google Doc with positioning
- Customer notes scattered across tools
- Conversations you had on a walk
Then came Bridesmaid. Christina and I built bridesmaid.love over a single Vibe Hackathon weekend – 48 hours from idea to deployment. The product itself shipped clean. What surprised me was what happened after. Getting the launch moving – landing pages, ads, a content cadence, the funnel – was slow and heavy in a way I couldn't place. I didn't really understand why it felt like there was so much to do, so much resistance.
Eventually I noticed what I had forgotten. I'd set up Bridesmaid's product context in the repo on day one. I had not done the same for the growth side. There was no docs/context/. No goals doc. No bottlenecks doc. No acquisition strategy. The agent that helped me build the product was working with half a brain every time I asked it to help me ship it.
Half of the company's brain was invisible to the agent I'd been working with all weekend.
This goes back to one of the first principles still on the Pirate Skills home page: build and grow have grown too far apart. The product lives in the codebase. The strategy and the marketing live in Notion, in slide decks, in Google Docs. AI Founder Mode last week made the architectural claim: the codebase is the company's brain. The piece you're reading now is what happens when you take that claim seriously enough to move the rest of the company in.
It doesn't have to stay split the way it is.
Build and Grow
in One Repo
I've been doing this at Pirate Skills for over a year. Not as a system anyone planned – it happened the way most useful patterns do, organically, file by file, by noticing what kept saving me time. By now the convention is settled enough that I run it as the opening move with every cohort that goes through the growth segment of Pirate Forge.
Two days ago I sat down with the current cohort and we did it from scratch, using Bridesmaid as the concrete worked example. The setup itself is simple: open the prompts from the Growth Codex's Growth Roadmap chapter one at a time inside Claude Code, answer each one out loud through Wispr Flow as the agent asks, and let the agent write the answers into markdown.
The prompt titles tell you what kind of questions land:
- Gather foundational business context for growth strategy
- Align growth goals with company vision and strategy
- Create OKRs for growth goals
- Identify bottlenecks in customer journey and operations
Plus a handful more. The file organization you'll see below isn't designed in advance – it falls out of running those prompts in order. The strategy that drives the product now lives in the same repo as the product.
The folder is docs/context/. One topic per file. The convention is short enough to fit in your head and explicit enough that you don't have to think about where anything goes.
Here's what each file does. business.md owns identity, value prop, customer segments, pricing – everything about what the company is and how it makes money, in one place. team.md names who decides what, and importantly, what other commitments constrain bandwidth. goals-and-targets.md carries the single north-star metric – for Bridesmaid right now, ten free trial starts per week, then double. bottlenecks.md names the binding constraint and the top three things that resolve it. vision-and-strategy.md holds the long-term direction and the operating principles. acquisition-strategy.md is the channel layer, where the actual go-to-market decisions live. And okrs.md holds the current cycle.
Each file cross-references the others inline with relative links. The agent walks the chain naturally. When it reads a bottlenecks.md item that points at founder bandwidth (see team.md#other-commitments), it follows the link and pulls the context. There's no separate index, no folder of context loaders, no chat-side prompt explaining where to look. The strategy is the index.
A codebase has the practical advantages everyone knows about – automatic saving, version history, diffs – but the one that actually matters for this workflow is more boring than that: it's the easiest place for an agent to search across every document at once, without reaching into another tool with weaker search.
The product and the strategy now share one repo, one memory, and one agent. This is also the same opening move I run with cohorts at the start of the Growth Codex roadmap's first chapters – strategy on day one, not in week eight, and not in a tool the team that actually has to execute it won't open.
The Knowledge Base
That Writes Itself
Here's the part that quietly changes everything. You already know the loop from last week's four-step skill loop – every working session ends with feedback that teaches the agent what was wrong, missing, or freshly learned, and updates the skill in the same breath. Point that same loop at docs/context/ and the strategy keeps itself current. No one sits down on a Sunday to update a process manual. The repo absorbs what you just figured out, and the next session starts from there.
A concrete example. Ask the agent to wire conversion tracking for a new Meta campaign on Bridesmaid. It doesn't need to ask which tool to use or which events to fire. It reads acquisition-strategy.md, which already specifies PostHog plus UTMs plus Meta CAPI as the attribution stack and lists the named conversion events each channel needs to track. It reads okrs.md, which makes paid-attributed trials a key result and forces the data to be reportable weekly. It finds the packages/analytics package already installed in the repo. Instrumentation lands on the first try, in the right places, with the right names.
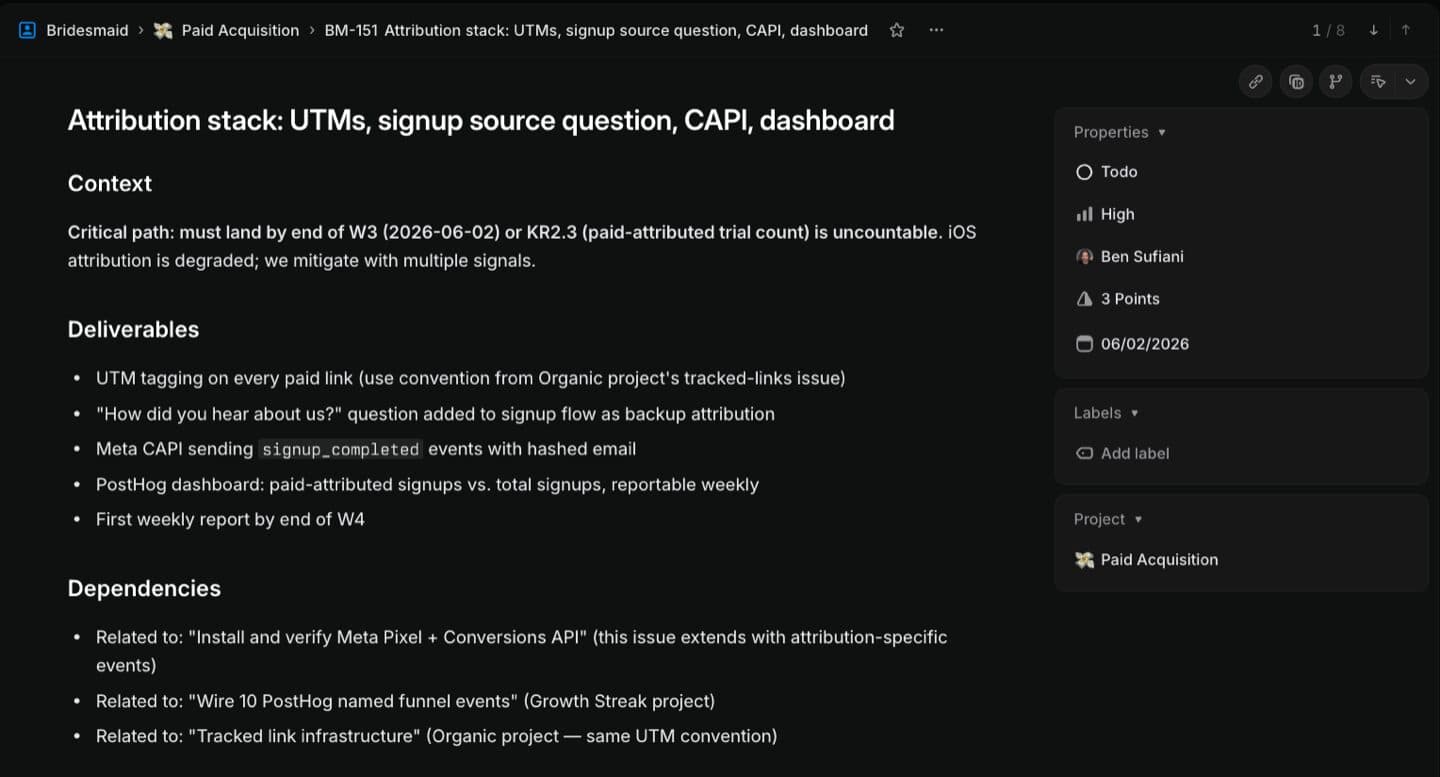
Without that context co-located, the agent either defaults to generic “track signup” boilerplate, or you spend twenty minutes pasting the event list and tool choice into every conversation. Multiplied across every refactor and every new feature, that's the difference between a system that compounds and one that re-derives from zero every Monday.
A second example, less obvious. Instagram and Pinterest content. The mistake is generating posts directly from business.md and vision-and-strategy.md. That jump is too raw. The actual flow is layered: strategy docs feed a derived content and storytelling framework that itself lives in docs/context/, and individual post drafts read from thatframework. Each layer is a real artifact in the repo. Each is aligned with the layer above it because the agent literally reads from the prior layer when building the next one. Improving the framework improves every post that comes after it – without you ever re-establishing the brand voice in a prompt. Compare to the Vibe Marketing Stack: that piece named the tools; this layer names what they read.
The same architecture quietly unlocks programmatic SEO templates the moment you reach for them: the city scope, the CTA pattern, the template choice are all already settled in the docs the generator reads from. You build the generator once; the strategy that aims it comes free.
The growth context lives where the agent looks. That single rule changes the cost of every downstream task. The feedback side of the loop is what keeps the rule true: when something surfaces in a conversation that the repo didn't know – a customer-segment correction, a pricing reframe, a competitor angle – the same conversation writes it back. The next session reads the updated version. Drift would require a second copy. There isn't one.
Strategy That Lands
In This Week's Cycle
The second half of the loop is where strategy stops being a doc and starts being a sprint. Once the strategy in docs/context/ is trustworthy, the same agent uses it to write the Linear projects and issues that execute it – no intermediate planning doc, no second copy to drift from.
At Bridesmaid, okrs.md carries three objectives – Organic Launch, Paid Acquisition, Growth Streak – each with two to four key results. The agent reads okrs.md together with the strategy around it (acquisition-strategy.md for channels, bottlenecks.md for what blocks each KR) and generates one Linear project per objective plus three to six issues per project. Each issue lands with its description pointing back to the file path and section it came from.
We don't do that transition by hand. The conversation stays inside Claude Code; the Linear MCP server is what reaches into Linear and writes the projects, the issues, the descriptions, the labels, the cycle assignment – everything. We never open the Linear app during the workshop. By the time we wrap, the strategy is in the repo and the cycle is standing in Linear, generated end-to-end by the agent.
### 🎯 O2 — Paid acquisition
into a working machine
- KR2.3 Paid-attributed trials
Baseline: 0
Target (by 2026-08-05):
≥ 100 paid-attributed trial starts
Measure: UTM attribution
+ "how did you hear about us?"
(see acquisition-strategy.md
for channel detail)Wire PostHog + Meta CAPI attribution
- UTMs on every paid link; “how did you hear about us?” added to signup as iOS-safe backup; Meta CAPI sending
signup_completedwith hashed email - Paid-attributed signup count reportable weekly from Week 4
This is the layer above Vibe Management. That piece showed Linear as the PM surface for execution; this section shows the Linear projects and issues themselves generated fromthe strategy living one folder up. The agent maintains the bidirectional link – every objective in okrs.md gets a Linear: <url> line appended underneath it; every Linear issue links back to its source file path in the description. When you click into a Linear issue and want to know why, the breadcrumb back to the strategy is one click. See the Growth Codex's How We Get There for the OKR-to-project mechanic this section operationalizes.
We've run this loop at Pirate Skills for over a year. Bridesmaid is the freshest demo, sized small enough that the whole pattern fits on one screen. The interesting thing is that the loop runs the same regardless of scale. The number of issues changes. The schema doesn't.
You haven't opened a PM tool to make any of this happen. And when the next conversation surfaces a new constraint, the same agent updates the relevant strategy file – okrs.md, acquisition-strategy.md, or wherever the constraint lives – regenerates the affected Linear issues, and the cycle reflects reality again. The strategy and the sprint share one substrate.
Run the Setup
This Afternoon
Three prompts. No restructuring. No new tools beyond Claude Code and Linear. We call it The Codebase Strategy Setup – paste each prompt into Claude Code in order, running in a fresh docs/context/ folder inside your product's repo. By the end your strategy lives in the same place your agents read from, and your Linear cycle stands up matching it.
The prompts are modelled on the Growth Codex lessons (the Founding Interview is essentially a compressed version of Where the Treasure Lies) – essentials only, no fluff. Total session length: about an hour.
Five essential questions. The agent writes four files.
business.mdteam.mdgoals-and-targets.mdbottlenecks.md
Agent reads the founding files and writes three more.
vision-and-strategy.mdacquisition-strategy.mdokrs.md
Account check, MCP install, then projects + issues generated from okrs.md.
- Workspace ready
- 1 Linear project per Objective
- 3–6 issues per KR
- Bidirectional links
Below are the three prompts in order. Copy each one into a fresh Claude Code conversation in your product's repo. Run them sequentially – each one waits on the files the previous one created.
That's the whole Codebase Strategy Setup. The first prompt seeds four files in about thirty minutes. The second derives the strategy layer in about fifteen. The third stands up Linear in another fifteen. By the end of the hour the strategy that drives your product lives in the place your agents already read from, and the cycle that executes it is standing in Linear.
From there the feedback loop carries it. Every working session does two jobs at once. Every correction edits the source. Strategy stops drifting because there is no second copy to drift from.
See Vibe Management for the execution layer this sits on top of, and AI Founder Mode for the architectural claim this extends. The growth segment of the Pirate Forge opens with exactly this setup – the rest of the cohort is six weeks of sharpening it in public.
See you on the bridge.
Cheers,
Ben
Ready to Go Deeper?
Pirate Lab
·Wed, Jul 29 · 18:00 CESTFree weekly online workshop where we walk through the week's Captain's Insight together. Bring your project, get live feedback.
Vibe Coding Cologne
·Wed, Aug 5 · 18:30 CESTMonthly in-person meetup in Cologne. Talks from Ben and local founders, drinks, building alongside the community.
Vibe Hackathon Cologne
·Fri, Sep 4 · 14:30 CESTIntensive on-site weekend hackathon – build and ship something real in 48 hours with other founders in Cologne.
Pirate Forge
·In 65 days · Wed, Sep 306-week cohort program combining build and grow tracks. Weekly workshops, accountability, the founders you'd want to ship next to.
Questions & Answers

Founder from Cologne with 15 years of startup experience across 9 ventures. After helping thousands master growth marketing, Ben learned vibe coding from scratch and launched CaptAIn within three months. He leads the Vibe Coding Cologne community, blending real founder experience with teaching clarity.